英伟达H100软件加持下AI性能比MI300X快47%

12月14日消息,AMD于本月初推出了其最强的AI芯片Instinct MI300X,其8-GPU服务器的AI性能比英伟达H100 8-GPU高出了60%。对此英伟达于近日发布了一组最新的H100与MI300X的性能对比数据,展示了H100如何使用正确的软件提供比MI300X更快的AI性能。
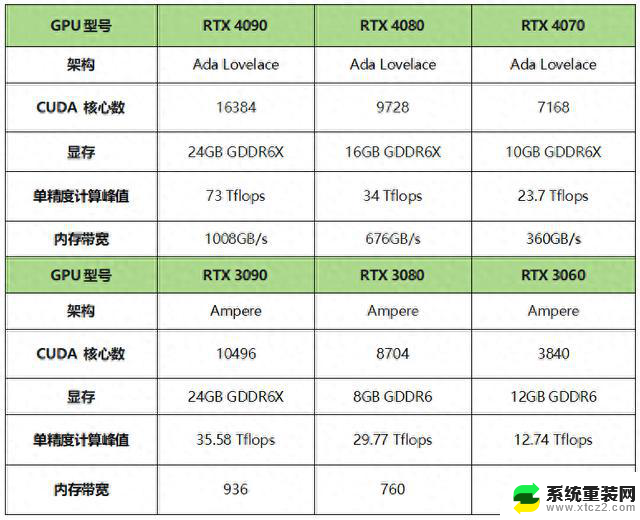
根据AMD此前公布的数据显示,MI300X的FP8/FP16性能都达到了英伟达(NVIDIA)H100的1.3倍,运行Llama 2 70B和FlashAttention 2 模型的速度比H100均快了20%。在8v8 服务器中,运行Llama 2 70B模型,MI300X比H100快了40%;运行Bloom 176B模型,MI300X比H100快了60%。
但是。需要指出的是,AMD在将MI300X 与 英伟达H100 进行比较时,AMD使用了最新的 ROCm 6.0 套件中的优化库(可支持最新的计算格式,例如 FP16、Bf16 和 FP8,包括 Sparsity等),才得到了这些数字。相比之下,对于英伟达H100则并未没有使用英伟达的 TensorRT-LLM 等优化软件加持情况下进行测试。
AMD对于英伟达H100测试的隐含声明显示,使用vLLM v.02.2.2推理软件和英伟达DGX H100系统,Llama 2 70B查询的输入序列长度为2048,输出序列长度为128。
而英伟达最新公布的对于DGX H100(带有8个NVIDIA H100 Tensor Core GPU,带有80 GB HBM3)测试,带有公开的NVIDIA TensorRT LLM软件,v0.5.0用于Batch-1,v0.6.1用于延迟阈值测量。工作量详细信息与脚注与AMD之前的测试相同。
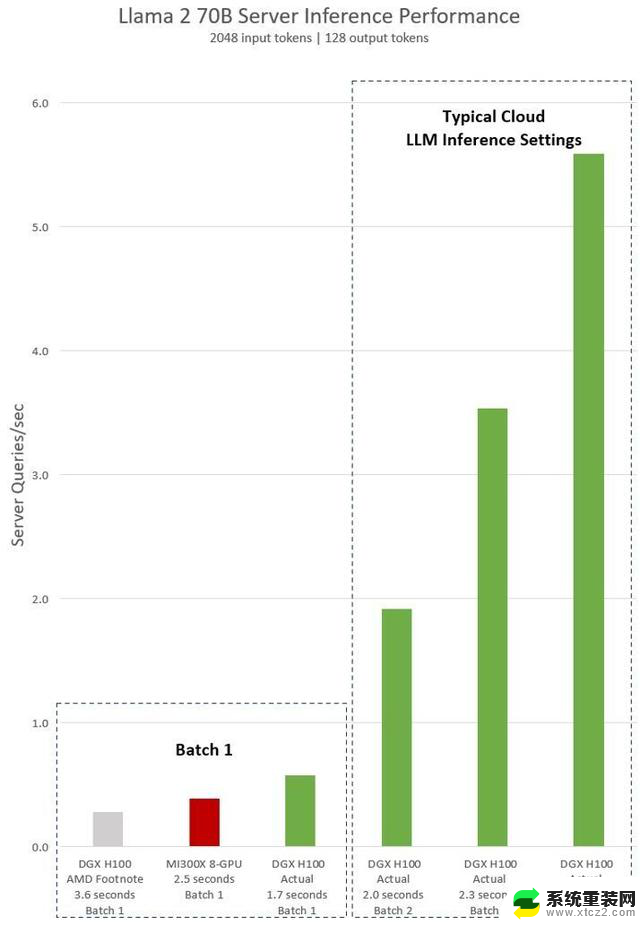
结果显示,与 AMD展示的MI300X 8-GPU服务器性能相比,英伟达DGX H100 服务器在使用优化的软件加持后,速度提高了 2 倍多,相比 AMD MI300X 8-GPU 服务器快了47%。
DGX H100 可以在1.7 秒内处理单个推理任务。为了优化响应时间和数据中心吞吐量,云服务为特定服务设置了固定的响应时间。这使他们能够将多个推理请求组合成更大的“Batch”,并增加服务器每秒的总体推理次数。MLPerf 等行业标准基准测试也使用此固定响应时间指标来衡量性能。
响应时间的微小权衡可能会导致服务器可以实时处理的推理请求数量产生不确定因素。使用固定的 2.5 秒响应时间预算,英伟达DGX H100 服务器每秒可以处理超过 5 个 Llama 2 70B 推理,而Batch-1每秒处理不到一个。
显然,英伟达使用这些新的基准测试是相对公平的,毕竟AMD也使用其优化的软件来评估其GPU的性能,所以为什么不在测试英伟达H100时也这样做呢?
要知道英伟达的软件堆栈围绕CUDA生态系统,经过多年的努力和开发,在人工智能市场拥有非常强大的地位,而AMD的ROCm 6.0是新的,尚未在现实场景中进行测试。
根据AMD之前透露的信息显示,其已经与微软、Meta等大公司达成了很大一部分交易,这些公司将其MI300X GPU视为英伟达H100解决方案的替代品。
AMD最新的Instinct MI300X预计将在2024年上半年大量出货,但是。届时英伟达更强的H200 GPU也将出货,2024下半年英伟达还将推出新一代的Blackwell B100。另外,英特尔也将会推出其新一代的AI芯片Gaudi 3。接下来,人工智能领域的竞争似乎会变得更加激烈。
编辑:芯智讯-浪客剑