NVIDIA-Merlin: 基于GPU的推荐系统训练和推理全套方案——加速推荐系统训练和推理的最佳选择
今天的介绍会围绕下面五点展开:
1. Merlin 产品概览
2. Merlin Models & Systems
3. Merlin Distributed Embeddings(TFDE)
4. 底层库:Merlin Hierarchical-KV
5. 推理的层次化参数服务器:Merlin Hierarchical Parameter Server(HPS)
分享嘉宾|王泽寰 NVIDIA 开发经理
编辑整理|闫玉芳
内容校对|李瑶
出品社区|DataFun
01
Merlin 产品概览
首先整体介绍一下 Merlin 产品。
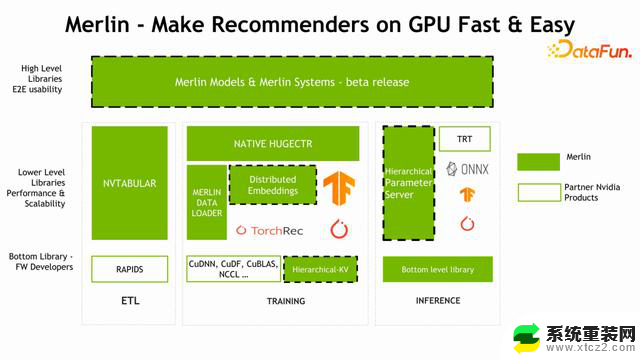
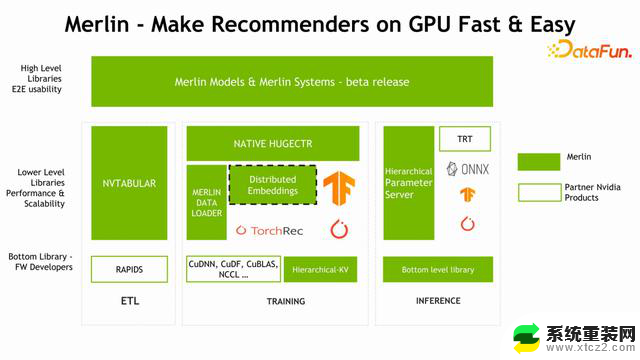
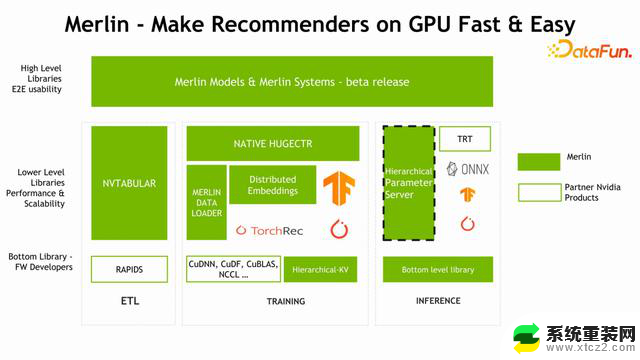
Merlin Models 和Merlin Systems,是比较高层的、方便用户部署和开发推荐系统模型的一套工具。下面最左面是 Feature Engineering ETL 的一个部分,它对应的 NVIDIA 组件叫 NVTABULAR。中间是针对训练部分的组件,也是 Merlin 优化的重点,包括我们比较熟悉的NATIVE HUGECTR、训练过程中加速训练数据读取的 Merlin DATA LOADER,以及今天会着重介绍的 Distributed Embedding(TensorFlow 的 Embedding 插件),还有比较底层的 C++库 HKV。训练之后要做部署,部署也涉及到很多工具,包括 HPS,在推理过程中加速 Embedding 的查找过程。
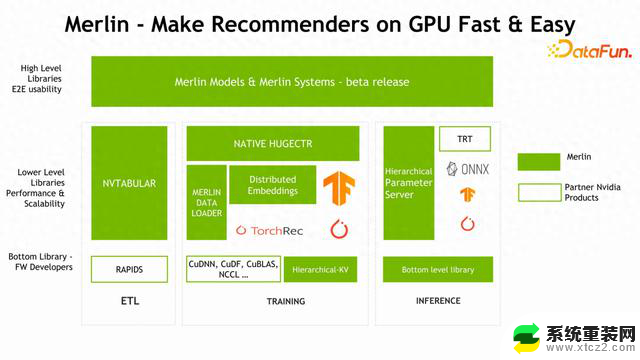
下图中高亮的四个部分是本次分享的重点,下面将依次展开介绍。
02
Merlin Models & Systems
1. Merlin Models
Merlin Models & Systems 是一个高层的库,方便用户用简单、快速的方法部署一个推荐系统的模型。主要面向需要快速上手、对推荐系统没有特别多开发经验的同学,目前的版本是beta release,具有的功能如下:
Merlin Models 的功能类似于我们熟悉的 Model Zoo,比如HUGGING FACE,包含了很多推荐系统的经典模型,例如 Facebook DLRM、Google DCN、YouTube DNN 等多种不同的模型。
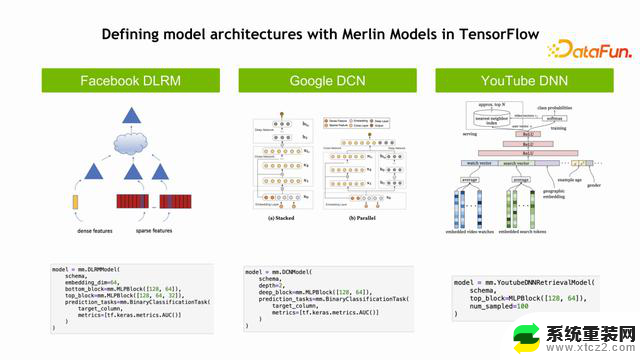
我们如何帮助用户简化他的开发和部署呢?一个很简单的方法是把这些模型包装起来,用户可以很简单地使用这些模型去配置,尝试使用这里面的模型去验证到底哪个模型最好。这里可以看到,只需一个简单的函数调用,简单的设定就可以把模型用起来,这些都是Python 中很简单的指令。
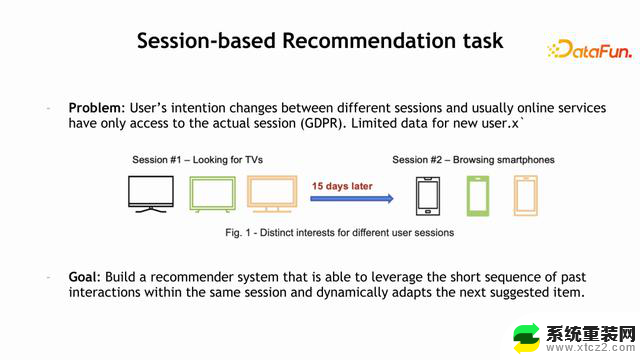
Merlin Models 中的一个亮点是 Session-based 模型。目前,推荐系统从全球来看,在用户获取数据时会受到一些限制,这些限制使得我们更难预测用户的下一步行为。那么如何解决这个问题呢?我们发现Session-based 模型对于这类问题有比较好的解决办法。在 Merlin Models 中加入了 Session-based 模型的支持,尤其是对比较短的 Sequence 进行预测,在这些需求下得到了一个比较好的效果,体现在最近的一个竞赛中。

Amazon KDD 的竞赛是大家广泛认识和熟悉的一个竞赛,在今年七月份,我们获得了优胜,大家如果对竞赛细节感兴趣,可以查阅相关的博客文章。
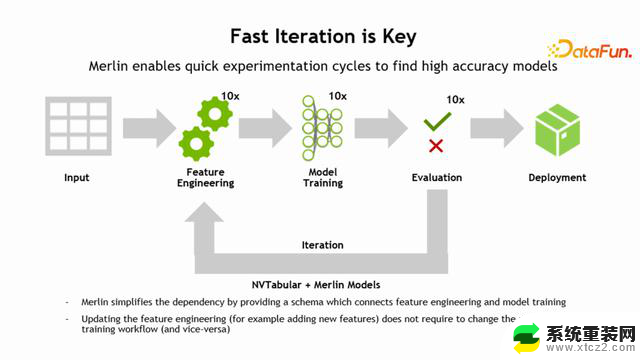
为了帮助用户进一步快速地进行模型的验证和上线,Merlin Models 和 NVTABULAR 有一个比较好的配合,进一步简化用户在调整特征、调整模型去进行组合验证过程中遇到的问题。传统上调整特征需要对 Tensorflow 模型代码进行一定的调整,而通过 schema 把 Merlin Models 和 NVTABULAR组合在一起解决了这个问题,特征调整不再需要手动修改代码。NVTABULAR 在进行特征工程之后可以生成 Schema,直接输入到 Model 中,然后去做训练,不需要对 Merlin Model 具体的模型细节进行调整,整个过程非常流畅,减轻了工程师的压力。
2. Merlin Systems
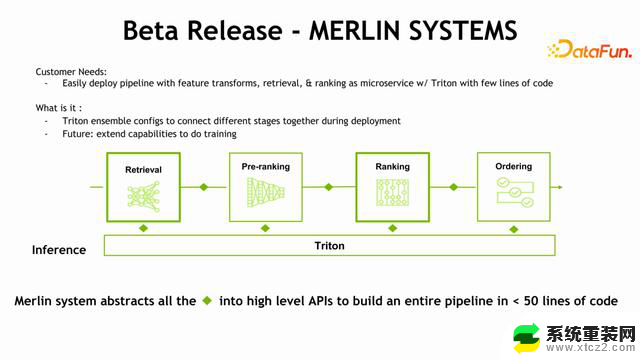
Merlin Models 主要是简化训练,而 Merlin Systems 更多的是简化推理和线上部署的过程。在 NV 的软件系统中,Triton 处于非常中心的位置,如果想要去部署推理的话,会用到 Triton,但是Triton 是一个综合性较强、并且通用的工具。推荐系统想要部署 Triton需要经过很多的配置,针对于 Retrieval、Pre-Ranking、Ranking、Ordering 做各种的配置,Merlin Systems 的工作是帮助用户简化这些配置,我们需要在同一个脚本中配置Retireval、Ranking,使用相关的几十行代码就可以部署上线。具体实现方式是对每一个过程进行抽象,上图中每一个菱形方块代表一个接口,在每个stage 之间,通过 API 相连,简单的配置 API,可以将整个流程串下来,就可以部署上线。

上图中的代码是具体的实现,可以看到,只需不到50行的代码就能够部署上线。
03
Merlin Distributed Embeddings(TFDE)
TFDE 是 Merlin中针对于 Tensorflow 设计的一个插件,这个插件提供了 Embedding API,用来加速 Embedding 的查找更新过程,使用它相当于使用TensorFlow 中稀疏的或稠密的 lookup。
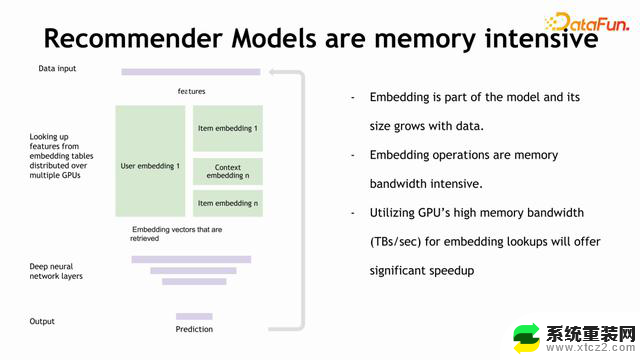
上图展示的是一个经典的问题,在我们推荐系统的模型中,Embedding 查找占据训练时间的主要部分,并且存在的一个问题是 Embedding非常大,然而深度学习网络往往只有几层。在推荐系统中加速 Embedding,是加速整个系统的核心。

TFDE 提供了一个很好的加速。上图中 Option 1 是一个纯 CPU 的实现,包括查 CUP 的 Embedding 加上 MLP;Option2 是一个比较常用的做法,在 GPU 上做 MLP 的计算,在 CPU 上去查 Embedding;Option3 是使用 GPU 的 Embedding和 GPU 的 MLP。在这三种不同的情况下,加速比还是很明显的。对于还在使用CPU 训练的同学,可以考虑尝试这种方式,会得到一个意想不到的效果,加速比可以达到 600 多倍。
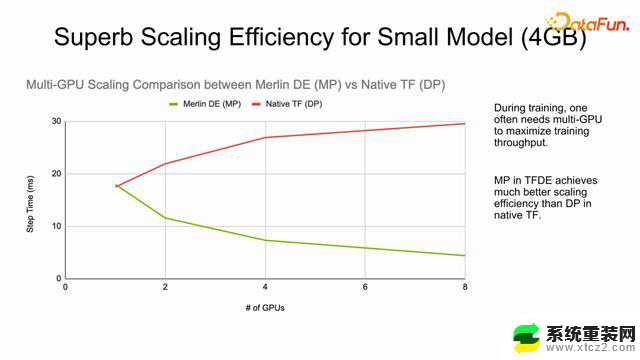
大模型需要使用很多的 GPU 去训练,distribute embedding 去处理大embedding 的问题,是不是小embedding 的加速效果会不好?如果没有很大的 embedding,是不是不应该用GPU 进行加速?当然不是。从上图可以看到,我们测试了 4GB 的小模型,一个GPU 完全可以放的下的情况,可以看到使用 TFDE 仍有明显的加速效果,其根本来自于传统的数据更新,也就是每个GPU 上有数据的拷贝,需要更新整个 Embedding 的 gradient。如果使用 TFDE 模型并行的方式只需要交换一个 feature map 就可以了,交换的数据量会大大减少。另外,还有我们做的 kernel的加速,综合起来会看到,即使是在非常小的模型下,使用 TFDE 在多 GPU 上运行时仍然比使用原生的 TensorFlow 有一个很好的加速效果。所以,无论是小模型还是大模型都可以尝试。
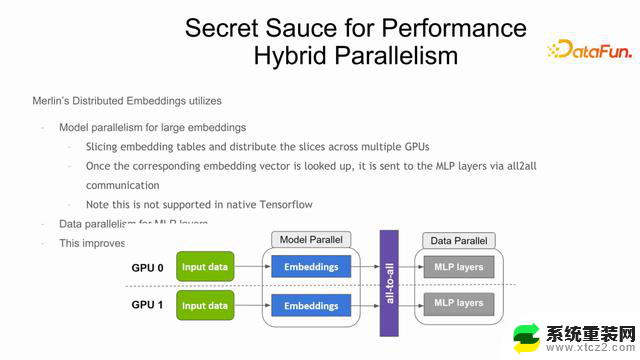
Embedding 加速机制是通过模型并行的方式分布在不同的 GPU 上,有时候多卡,有时候是多机。在多卡上进行模型并行查找之后,进行 allTOall,去进行数据交换,让dense 部分还是使用数据并行的方式,也就是模型并行加数据并行的一个模式,来加速整个推荐系统的训练过程。

TFDE 的使用方法很简单,它作为一个 Tensorflow 插件,其实并不需要花很多的精力改造原有的程序,只需按照上图高亮的部分进行简单的更改即可。首先,构建模型时,更改embedding layer。原来会有一组 embedding 构建出来,然后将这一组embedding 输入给 DistributedEmbedding 的构造函数,构造出来一个新的embedding layer,相当于进行一个翻译,翻译成 TFDE 的embedding layer。第二步修改,是在 training step中数据交换部分,使用 DistributedGradientTape 函数。最后一步,是在做 embedding 的初始化时,将参数初始化在不同的 GPU 里。操作时要用到broadcast_variables 这样一个函数去进行参数初始化。通过以上三步的修改就可以将程序跑起来。

在推荐系统中,我们常用的训练方式是 continuous training,支持将增量的模型导出来。第二个是 GPU-CPU offloading,有些算子可以offload 到 CPU 中,更贴近原生的 Tensorflow 的支持。另外,现在比较依赖于原生的 Horovod,后面还会做得更加易用,并进一步提升性能。
04
Merlin Hierarchical-KV

这个库是位于 Merlin 最底层的C++ 的一个库,完成 key、value 的基本的操作。

它支持分布式的、层次化的内存,key、value 支持 eviction,这个库是针对推荐系统训练的场景来做的,在推荐系统训练的场景下有很好的支持和性能。这个库的优点有如下几个方面:
1. 支持 CPU和 GPU 存储的结合
将其看作 unifiedmemory 就可以。
2. 有很好的性能
在整个查找过程中由 GPU 来操作计算,并不需要CPU 进行额外的计算,可以腾出来宝贵的 CPU 资源。
3. 支持 eviction
支持丰富的 eviction 规则,例如LRU、LFU 等一些淘汰规则,还可以支持用户定制化的一些规则,从而最大程度上保证HKV 上的命中率。
4. 整体性能稳定
即使在 load factor 为1.0 时也能达到很稳定的性能,并不会在插入很多的情况下,导致系统变得很慢。
5. 容易加入到不同训练的 framework 里面,方便用户使用
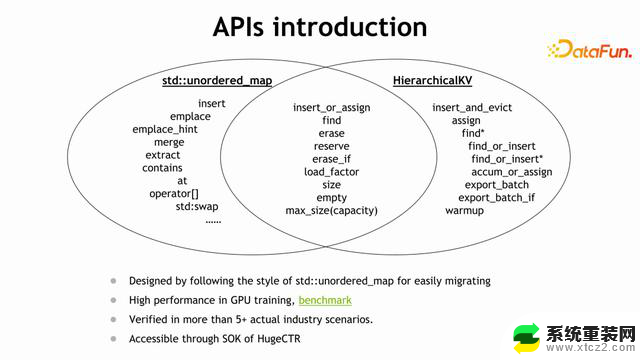
这个 C++ 库和 std::unordered_map 的 API 十分相似,也有丰富的交集,熟悉unordered_map 再使用 HKV,很容易上手。但明显的区别是一个在CPU 上,一个是在 GPU 上。在 GPU 上训练的性能,可以参考这个链接(https://github.com/NVIDIA-Merlin/HierarchicalKV#benchmark--performancewip),这个库已经在很多公司进行使用,在即将发布的版本中,也可以看到SOK 和 HKV 很好的结合使用。

HKV 比较有趣的功能是支持 Cache mode,将 HKV 当作一个 Cache 来用,可以接入用户的 PS,如果在 HKV 中查不到的话,可以到用户的 PS 中查找,Backward 时,也可以更新到用户的 PS 中去。在训练过程中使用,有两个strategy,一个是前向的查找和后向的查找和插入;另外一个策略是,在查找时,就能够将数据 insert 到哈希表中,backward 时更新数据就只需要 assign 就可以了。更详细的 API 说明可以参考这个链接 https://nvidia-merlin.github.io/HierarchicalKV/master/api/index.html。
05
推理的层次化参数服务器:Merlin Hierarchical Parameter Server(HPS)
推理过程使用的工具,叫 Hierarchical Parameter Server,TFDE 是在训练过程中加速 embedding 的一个工作,HPS 是在推理过程中加速推理 embedding 的工作。
推荐系统的数据集具有非常显著的特点:0.16%的特征会占据 95.9% 的样本,可以看到重复性非常的高。基于这样的数据特点,做了下图中的 GPU cache。
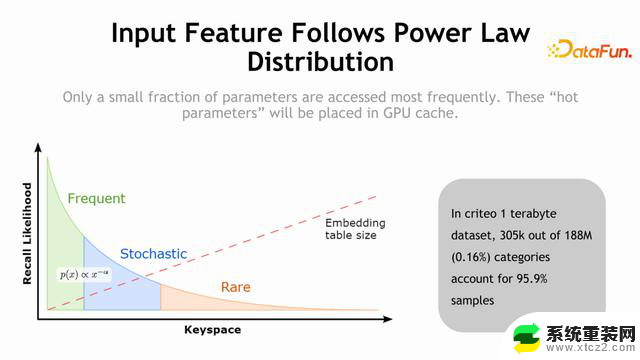
只需要很小的 cache 就可以将很多的数据流量cache 到 GPU 中,不需要去 CPU 中找了,一方面减少了 CPU 参数服务器的压力,同时也减少了数据传输的时间,另外在GPU 中进行查找非常快,查找过程本身也得到了很好的加速。因此,设计了 HPS这样一个工具,用来加速推荐系统中的推理。
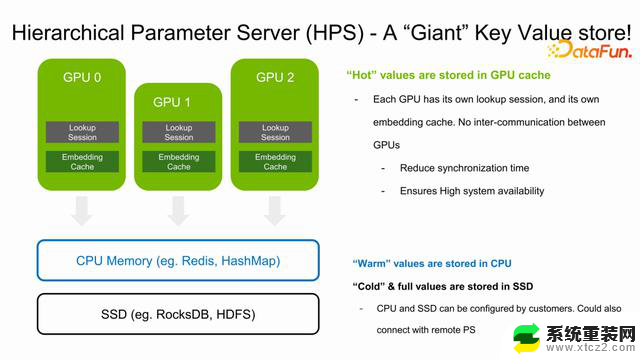
上图中是 HPS 的结构,在推理过程中推荐在每一个GPU 中部署一个lookup 的 session,每一个 lookup 的 session 相当于是一个 worker,来完成用户的查找工作。下面每一个 GPU 上都有一个 Embedding cache,cache 每一个 GPU 上热点的 feature,如果 cache不住,会去 CPU memory 及 SSD 中查找,这同时也依赖于使用的是什么backend database,例如 RocksDB、HDFS 等。
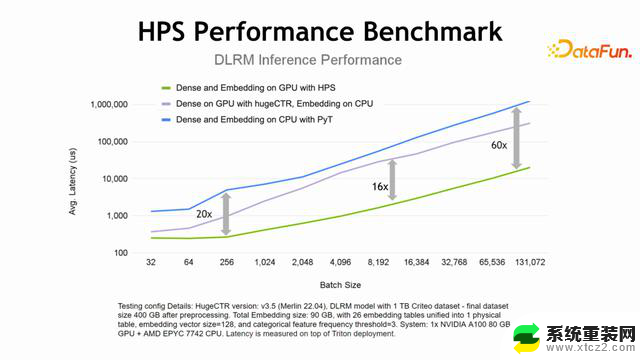
在性能方面,我们在DLRM模型上做了一些测试。测试分成三个部分:蓝线代表使用CPU 去做 dense 部分,也使用 CPU 去做 embedding 部分的查找计算;绿线代表所有的部分都使用GPU,使用 HPS 作为 embedding的 PS,dense 部分使用 Pytorch 的 GPU 的模块;紫色部分模拟的是使用GPU 来进行 MLP dense 部分,使用 CPU 来做 embedding 的查找。通过三个部分的对比得到了上图,图中,纵轴表示延迟,横轴表示batchsize,可以看到,即使是很小的 batchsize,蓝色线也能达到很好的性能。针对GPU 来做 dense 部分,CPU 来做 embedding 的查找可以考虑使用这个方案。
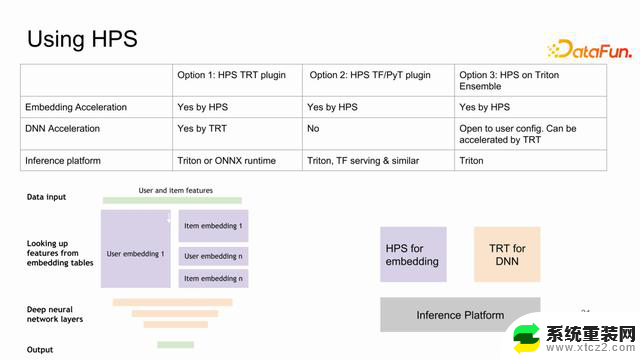
在易用性方面,是否容易尝试,是否容易集成呢?HPS针对不同场景设计了一些 plugin,包括 TRT plugin、PyT plugin 以及 HPS on Triton Ensenble,无论使用哪种方式,都对推荐系统的推理有很好的加速效果。其中,加速效果最好的是TRT plugin。dense 部分和 embedding 部分都可以很好地使用 GPU 进行加速,而且对中间部分的衔接也有很好的处理。需要在推理中使用TF 或者 PyT 的用户可以使用 TF/PyT plugin。针对其他的框架,可以使用 Triton Ensemble 模式。
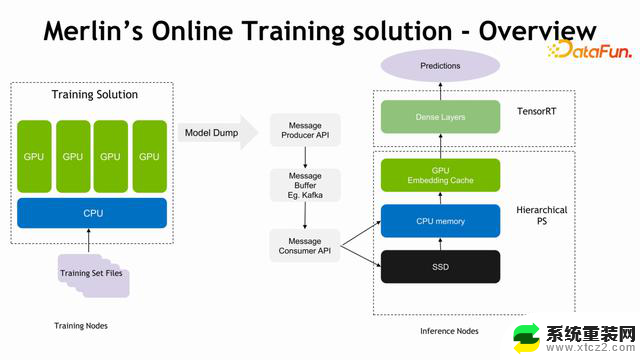
在推荐系统中,经常会有 continue training,训练时会有增量的模型导出出来,导出后希望推理的服务器能够接收这种模型的增量来进行推理。在整个过程中如何减少推理服务器的延迟,是HPS 中一个非常重要的工作。在训练过程中,可以使用 Kafka 将增量的模型推出来,推到线上的服务器,HPS 可以使用小步快跑的方式,将 embedding 进行一个少量的迭代,进行一些替换,这样可以把整个推理的延迟降到一个比较低的水平。整个推理的过程取决于中间的软硬件条件,比如训练服务器和推理服务器中间的网络接口和使用什么样的软件工具进行加速。HPS 主要完成后面的,小步替代的功能,性能依赖于中间的传输接口。


如果对这部分感兴趣可以看一下上面的课程以及相关的资料。
以上就是本次分享的内容,谢谢大家。